








Breaking News
 Rep. Massie Proposes NDAA Amendment Preventing Integration of IDF with US Military
Rep. Massie Proposes NDAA Amendment Preventing Integration of IDF with US Military
 Liberals Have Relaxed About Trump Because They Trust Him To Keep the Wars Going
Liberals Have Relaxed About Trump Because They Trust Him To Keep the Wars Going
 LIVE Coverage of President Trump's Historic Speech Exposing Communist Chinese & Their Allies'
LIVE Coverage of President Trump's Historic Speech Exposing Communist Chinese & Their Allies'
 The Next Recession? What Americans Need To Know |Jiang Xueqin Explainer
The Next Recession? What Americans Need To Know |Jiang Xueqin Explainer
Top Tech News
 Chinese researchers have developed a sodium-metal battery that can fully charge in just 4 minutes...
Chinese researchers have developed a sodium-metal battery that can fully charge in just 4 minutes...
 SpaceX Starship Flight 13 in 3 Days - Thursday July 13
SpaceX Starship Flight 13 in 3 Days - Thursday July 13
 Chinese Scientists Develop Nuclear Battery Using Carbon-14
Chinese Scientists Develop Nuclear Battery Using Carbon-14
 Teleoperated humanoid robots complete first-ever live surgery
Teleoperated humanoid robots complete first-ever live surgery
 Floating capsule auto-disinfects water without chemicals or battery
Floating capsule auto-disinfects water without chemicals or battery
 Modular Reactors To Solve Data Center Hysteria?
Modular Reactors To Solve Data Center Hysteria?
 DeepSeek Developing In-House AI Chip In Bid To Cut Nvidia Reliance
DeepSeek Developing In-House AI Chip In Bid To Cut Nvidia Reliance
 America just took three brand-new nuclear reactors critical in thirty days, a first for any...
America just took three brand-new nuclear reactors critical in thirty days, a first for any...
 Your brain doesn't peak in your 20s after all: Study reveals your mind is at its sharpest betwee
Your brain doesn't peak in your 20s after all: Study reveals your mind is at its sharpest betwee
 Compasses, not maps: China is building a different type of AI
Compasses, not maps: China is building a different type of AI



AI AlphaGo Zero started from scratch to become best at Chess, Go and Japanese Chess within hours
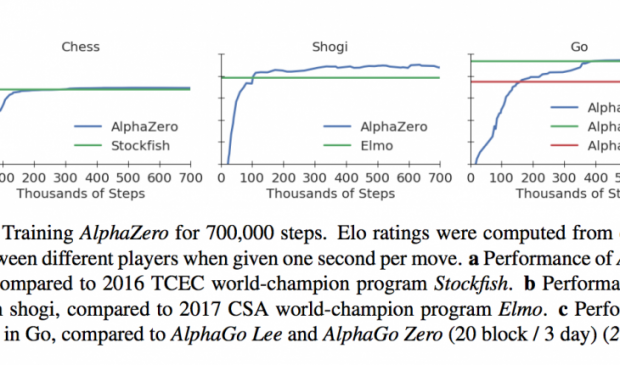
Starting from random play, and given no domain knowledge except the game rules, AlphaZero achieved within 24 hours a superhuman level of play in the games of chess and shogi (Japanese chess) as well as Go, and convincingly defeated a world-champion program in each case.
Self-play games are generated by using the latest parameters for this neural network, omitting
the evaluation step and the selection of best player.
AlphaGo Zero tuned the hyper-parameter of its search by Bayesian optimization. In AlphaZero they reuse the same hyper-parameters for all games without game-specific tuning. The sole exception is the noise that is added to the prior policy to ensure exploration; this is scaled in proportion to the typical number of legal moves for that game type.
Like AlphaGo Zero, the board state is encoded by spatial planes based only on the basic
rules for each game. The actions are encoded by either spatial planes or a flat vector, again
based only on the basic rules for each game.