








Breaking News
 Elon Musk The Economist July 23rd 2026 - FULL Interview
Elon Musk The Economist July 23rd 2026 - FULL Interview
 Meltdown? The Real Reason Why The Media Hates Elon Musk
Meltdown? The Real Reason Why The Media Hates Elon Musk
 Bitcoin Debate: Pomp DESTROYS Peter Schiff
Bitcoin Debate: Pomp DESTROYS Peter Schiff
 Oil shipments are under attack on multiple fronts as fighting escalates in Red Sea, Hormuz...
Oil shipments are under attack on multiple fronts as fighting escalates in Red Sea, Hormuz...
Top Tech News
 Elon Vows AI-Made 'Odyssey' After Blasting Nolan's Take On Homer
Elon Vows AI-Made 'Odyssey' After Blasting Nolan's Take On Homer
 Anthropic is launching its own drug discovery programs for rare diseases using Claude...
Anthropic is launching its own drug discovery programs for rare diseases using Claude...
 SpaceX AI Satellites Will Have 250 Kilowatts of Power
SpaceX AI Satellites Will Have 250 Kilowatts of Power
 Chinese researchers have developed a sodium-metal battery that can fully charge in just 4 minutes...
Chinese researchers have developed a sodium-metal battery that can fully charge in just 4 minutes...
 SpaceX Starship Flight 13 in 3 Days - Thursday July 13
SpaceX Starship Flight 13 in 3 Days - Thursday July 13
 Chinese Scientists Develop Nuclear Battery Using Carbon-14
Chinese Scientists Develop Nuclear Battery Using Carbon-14
 Teleoperated humanoid robots complete first-ever live surgery
Teleoperated humanoid robots complete first-ever live surgery
 Floating capsule auto-disinfects water without chemicals or battery
Floating capsule auto-disinfects water without chemicals or battery
 Modular Reactors To Solve Data Center Hysteria?
Modular Reactors To Solve Data Center Hysteria?
 DeepSeek Developing In-House AI Chip In Bid To Cut Nvidia Reliance
DeepSeek Developing In-House AI Chip In Bid To Cut Nvidia Reliance



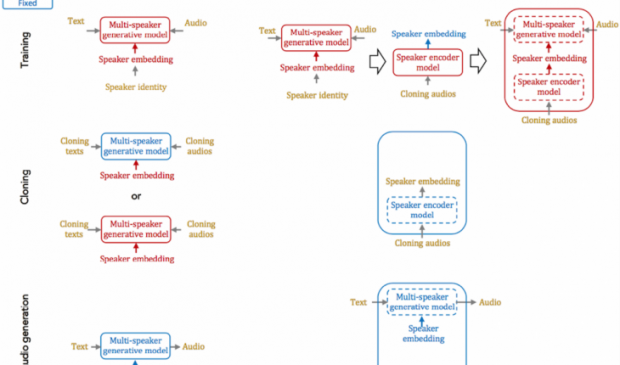
AI voice cloning from a few seconds of voice sampling is real and rapidly improving
There are examples of speech sample recordings and synthesized speech based on different numbers of samples. The synthesized speech had some noise distortion but the samples did sound like the original speakers.
Baidu attempted to learn speaker characteristics from only a few utterances (i.e., sentences of few seconds duration). This problem is commonly known as "voice cloning." Voice cloning is expected to have significant applications in the direction of personalization in human-machine interfaces.
They tried two fundamental approaches for solving the problems with voice cloning: speaker adaptation and speaker encoding.
Speaker adaptation is based on fine-tuning a multi-speaker generative model with a few cloning samples, by using backpropagation-based optimization. Adaptation can be applied to the whole model, or only the low-dimensional speaker embeddings. The latter enables a much lower number of parameters to represent each speaker, albeit it yields a longer cloning time and lower audio quality.