








Breaking News
 Our Food Reserves Are Vanishing THE 22% SUPPLY COLLAPSE JUST HAPPENED.
Our Food Reserves Are Vanishing THE 22% SUPPLY COLLAPSE JUST HAPPENED.
 Sneak peek at the new summer kitchen and butcher shop and showcasing a new survival product.
Sneak peek at the new summer kitchen and butcher shop and showcasing a new survival product.
 Trump abruptly kills his Strait of Hormuz toll after just one day...
Trump abruptly kills his Strait of Hormuz toll after just one day...
 Polybee and Vegetables by Bayer ink new partnership
Polybee and Vegetables by Bayer ink new partnership
Top Tech News
 Modular Reactors To Solve Data Center Hysteria?
Modular Reactors To Solve Data Center Hysteria?
 DeepSeek Developing In-House AI Chip In Bid To Cut Nvidia Reliance
DeepSeek Developing In-House AI Chip In Bid To Cut Nvidia Reliance
 America just took three brand-new nuclear reactors critical in thirty days, a first for any...
America just took three brand-new nuclear reactors critical in thirty days, a first for any...
 Your brain doesn't peak in your 20s after all: Study reveals your mind is at its sharpest betwee
Your brain doesn't peak in your 20s after all: Study reveals your mind is at its sharpest betwee
 Compasses, not maps: China is building a different type of AI
Compasses, not maps: China is building a different type of AI
 The Return of the Ekranoplan
The Return of the Ekranoplan Farewell, atom-smashing Large Hadron Collider
Farewell, atom-smashing Large Hadron Collider
 This is already starting.
This is already starting.
 The Crosley IcyBall
The Crosley IcyBall It's Not a Conspiracy Anymore: Med Beds Exist and Trump Knows It
It's Not a Conspiracy Anymore: Med Beds Exist and Trump Knows It



Three Eras of Machine Learning and Predicting the Future of AI
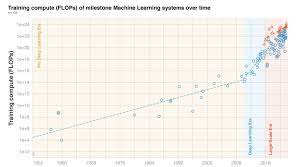
They show :
before 2010 training compute grew in line with Moore's law, doubling roughly every 20 months.
Deep Learning started in the early 2010s and the scaling of training compute has accelerated, doubling approximately every 6 months.
In late 2015, a new trend emerged as firms developed large-scale ML models with 10 to 100-fold larger requirements in training compute.
Based on these observations they split the history of compute in ML into three eras: the Pre Deep Learning Era, the Deep Learning Era and the Large-Scale Era . Overall, the work highlights the fast-growing compute requirements for training advanced ML systems.
They have detailed investigation into the compute demand of milestone ML models over time. They make the following contributions:
1. They curate a dataset of 123 milestone Machine Learning systems, annotated with the compute it took to train them.