








Breaking News
 The Great Rotation Has Begun... Here's How to Make Your Money Back
The Great Rotation Has Begun... Here's How to Make Your Money Back
 Blue Origin plans to fly New Glenn rocket again this year despite massive rocket explosion
Blue Origin plans to fly New Glenn rocket again this year despite massive rocket explosion
 Through Technology, a Centuries-Old Battle Is Coming to a Head
Through Technology, a Centuries-Old Battle Is Coming to a Head
 Chinese cars go blacker than black via hybrid nano tech
Chinese cars go blacker than black via hybrid nano tech
Top Tech News
 'Groundbreaking' Potential Lupus Cure Sends Patients into Remission, Allowing Dreams...
'Groundbreaking' Potential Lupus Cure Sends Patients into Remission, Allowing Dreams...
 Speculations on What Could Show Physics Beyond the Standard Model
Speculations on What Could Show Physics Beyond the Standard Model
 SpaceX Orbital Travel and Orbital Hotels Need Starfall – Getting Back Safe and Cheap is Exciting
SpaceX Orbital Travel and Orbital Hotels Need Starfall – Getting Back Safe and Cheap is Exciting
 Lizard-inspired wiggly wheels let Mars rover swim through sand
Lizard-inspired wiggly wheels let Mars rover swim through sand
 Fact Sheet: President Donald J. Trump Ushers in the Next Frontier of Quantum Innovation
Fact Sheet: President Donald J. Trump Ushers in the Next Frontier of Quantum Innovation
 Researchers at Johns Hopkins University just let an AI-guided robot remove a dead pig's gallblad
Researchers at Johns Hopkins University just let an AI-guided robot remove a dead pig's gallblad
 World's first consumer wing-in-ground effect aircraft takes flight
World's first consumer wing-in-ground effect aircraft takes flight
 America's Military Readiness Depends On Deployable Nuclear Power
America's Military Readiness Depends On Deployable Nuclear Power
 License Plate Cameras Are About To Start Tracking A Lot More Than Just Your Car
License Plate Cameras Are About To Start Tracking A Lot More Than Just Your Car
 Heads up: Apparently the government is hiding cameras inside fake utility boxes
Heads up: Apparently the government is hiding cameras inside fake utility boxes



Beyond Big Data is Big Memory Computing for 100X Speed
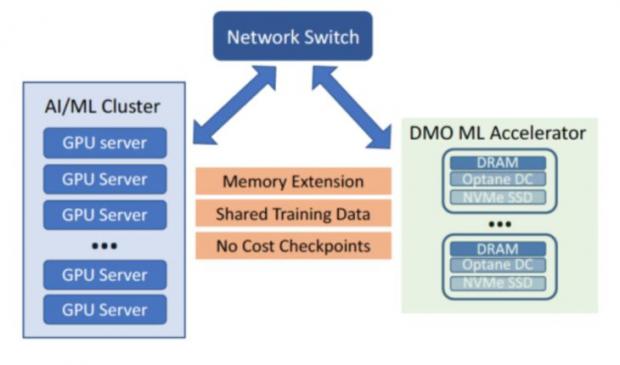
This new category is sparking a revolution in data center architecture where all applications will run in memory. Until now, in-memory computing has been restricted to a select range of workloads due to the limited capacity and volatility of DRAM and the lack of software for high availability. Big Memory Computing is the combination of DRAM, persistent memory and Memory Machine software technologies, where the memory is abundant, persistent and highly available.
Transparent Memory Service
Scale-out to Big Memory configurations.
100x more than current memory.
No application changes.
Big Memory Machine Learning and AI
* The model and feature libaries today are often placed between DRAM and SSD due to insufficient DRAM capacity, causing slower performance
* MemVerge Memory Machine bring together the capacity of DRAM and PMEM of the cluster together, allowing the model and feature libraries to be all in memory.
* Transaction per second (TPS) can be increased 4X, while the latency of inference can be improved 100X